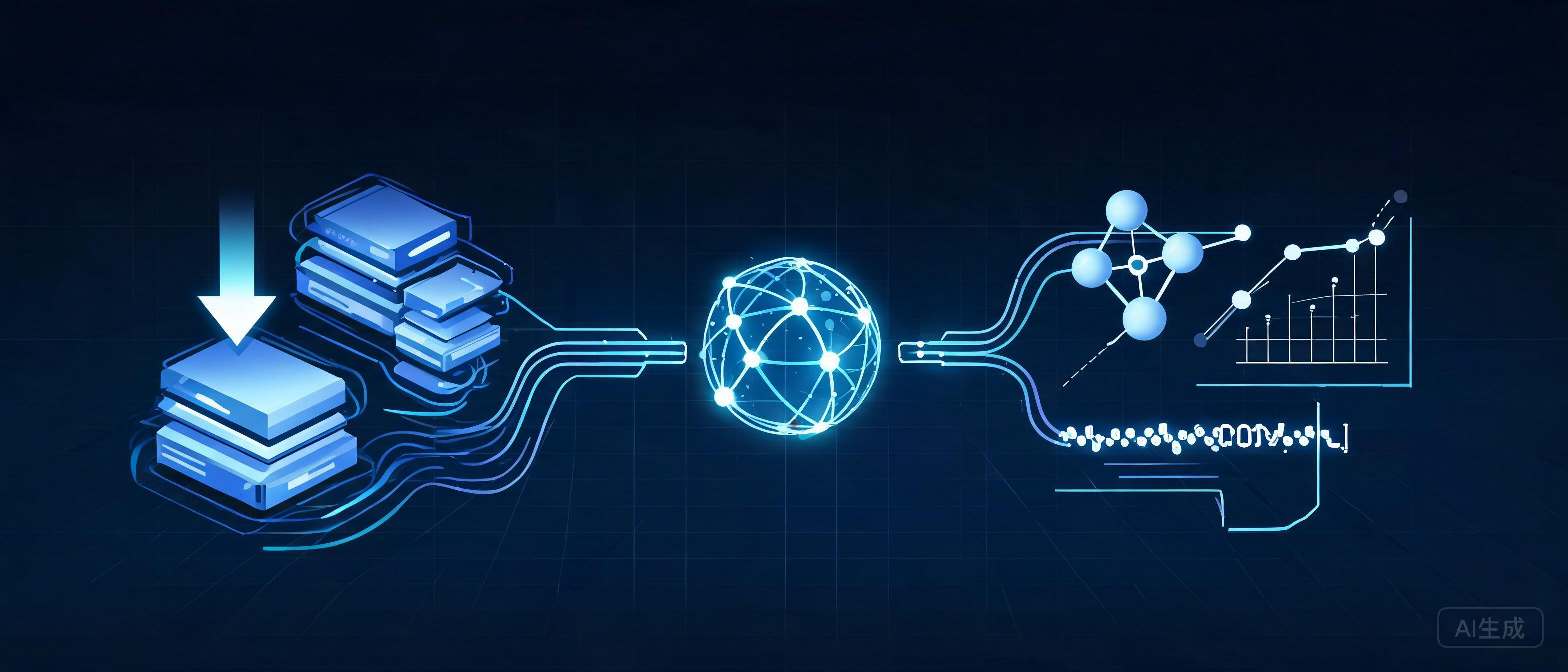
在 AI 浪潮席卷数据库行业的今天,OceanBase 给出了一套激进的解答。7 月 1 日,OceanBase CTO 杨传辉在公开分享中正式发布了湖库一体(OceanBase Lakebase)AI 数据库,核心思路是用一套技术栈实现离在线统一,将实时事务能力与湖上开放存储、开放计算能力融合进同一个数据底座。

杨传辉指出,AI 时代正在从三个层面颠覆数据库的既有定义:使用者从人类应用扩展到大量自主运行的 AI Agent;管理的数据从结构化扩展到结构化、半结构化与非结构化的多模态;承载的工作负载从事务和分析扩展到搜索、上下文工程与 AI 应用。在他看来,AI 数据库不是传统数据库增加几个 AI 函数,也不是向量数据库补上 SQL 能力,而是要解决 AI 进入生产系统后的数据基础设施问题。