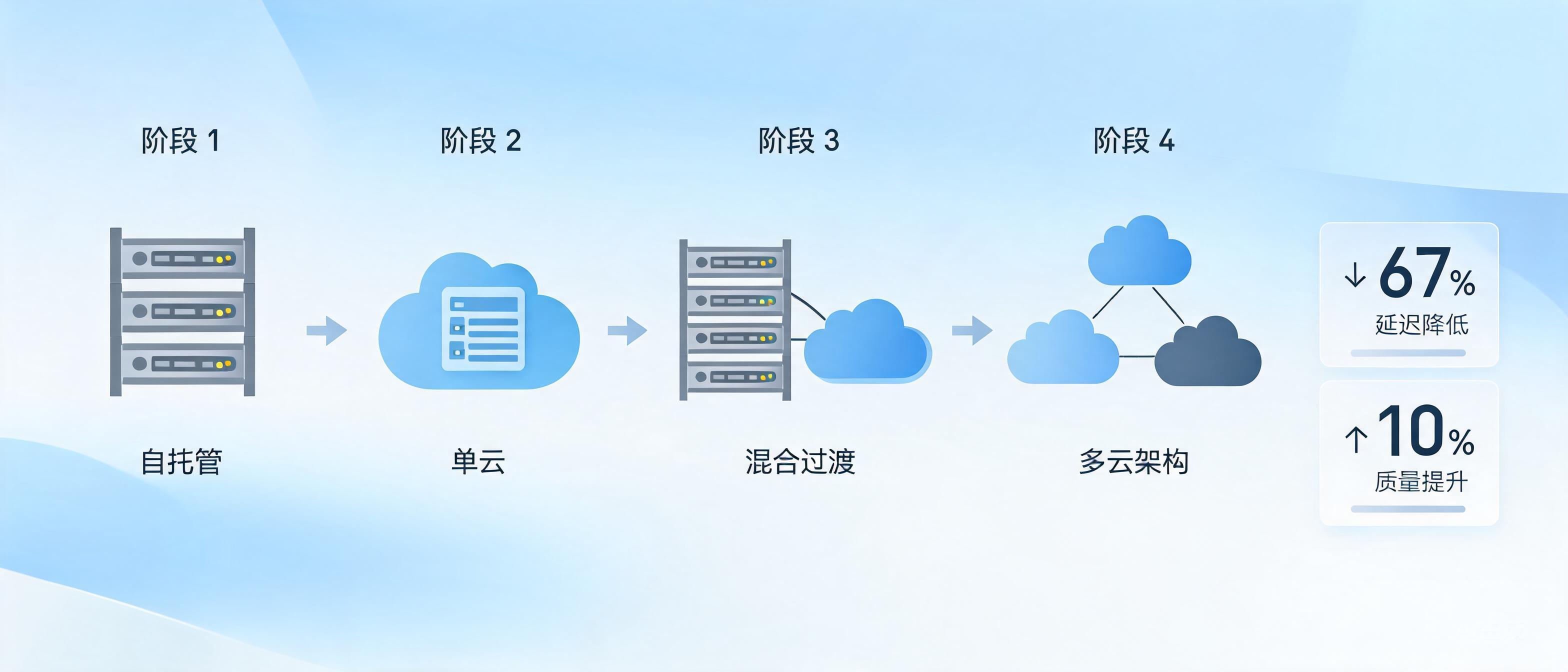
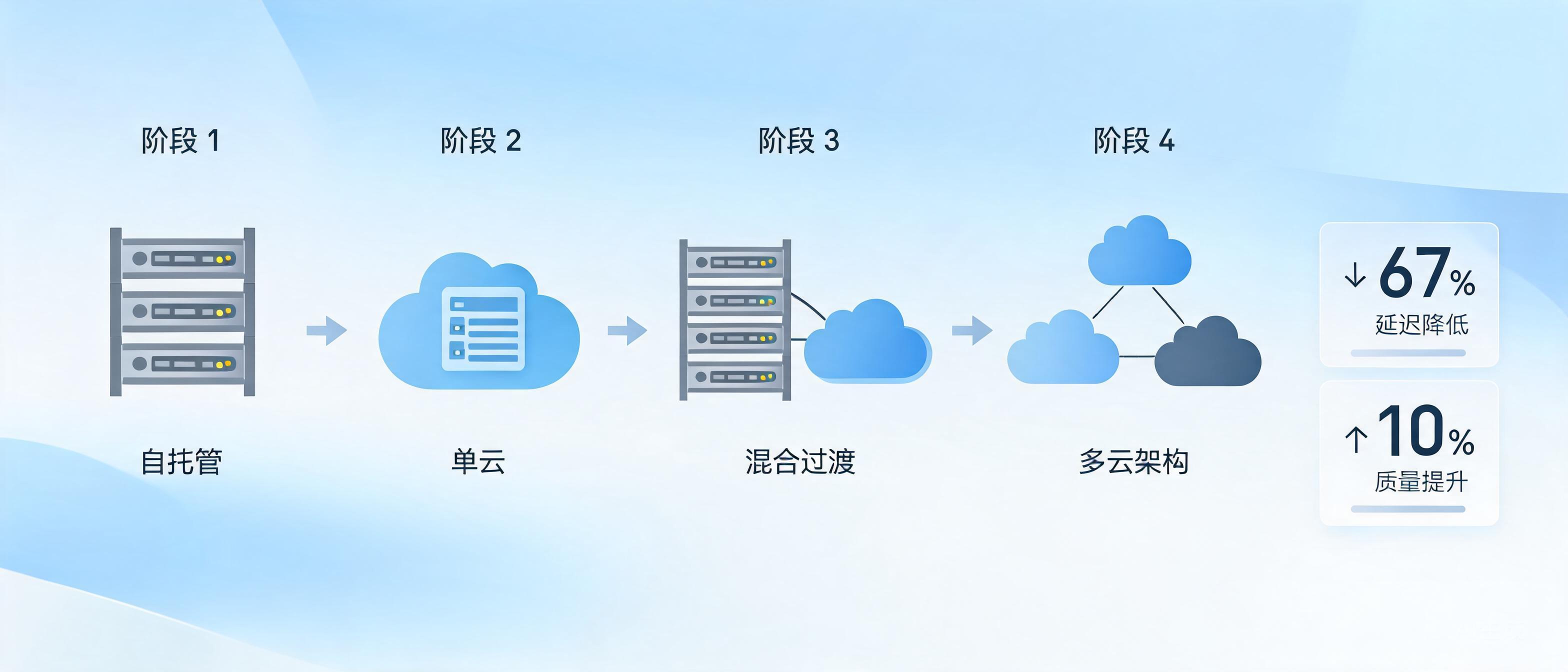
企业协作平台 Slack 近日详细披露了其 AI 服务基础设施从单云自托管演进为多云架构的完整路径,展示了如何通过四个阶段的迭代解决容量规划、供应商锁定和弹性等关键挑战。据 Slack 官方报告,最终的多云配置使复杂推理工作负载的质量提高了约 10%,同时将短提示词的延迟降低了约 67%。
点击查看原文>
企业协作平台 Slack 近日详细披露了其 AI 服务基础设施从单云自托管演进为多云架构的完整路径,展示了如何通过四个阶段的迭代解决容量规划、供应商锁定和弹性等关键挑战。据 Slack 官方报告,最终的多云配置使复杂推理工作负载的质量提高了约 10%,同时将短提示词的延迟降低了约 67%。
Slack 的 AI 服务平台最初运行在 Amazon SageMaker 上,采用跨账户 IAM 角色并置于托管 VPC 中。这种架构虽然提供了强大的隔离性,但运维负担沉重:工程师需要手动进行容量预测、按计划扩展集群,并提前规划稀缺的 A100 和 H100 GPU 资源。由于每天有数百万用户依赖 AI 驱动的功能,容量不足和基础设施问题会迅速演变为影响客户的严重事件。
为减轻运维压力,Slack 将 AI 服务迁移至 Amazon Bedrock。这一举措消除了基础设施管理的开销,缩短了功能上线延迟,并使其能够更快地访问 Anthropic 的新模型。工程师不再需要直接管理 GPU 预留,从而将精力聚焦于模型性能和产品质量。Slack 通过合规性审查、负载测试以及基于功能开关的分阶段部署完成了这次迁移,据称期间未发生任何影响客户的事件。
然而,流量波动成为新的挑战。Slack 报告称,AI 工作负载在高峰期和非高峰期之间的波动幅度可达 10 倍。为应对这一问题,团队将 Bedrock 的“预配置吞吐量”(PT)与“按需”服务相结合:交互式流量被路由到延迟更低的 PT 端点,而突发性的后台工作负载则溢出到“按需”容量中。这种混合容量模型有效解决了扩展难题,但 Slack 指出,其 AI 平台仍然依赖于单一供应商,这引发了弹性方面的担忧,并限制了他们使用与 AWS 存在竞争关系的生态系统的模型。
对单一供应商的依赖促使 Slack 采取多云战略。要集成 Google Cloud Vertex AI,该公司需要构建一个与供应商无关的部署层,使其能够在各种云环境中一致地运行。该平台引入了无密钥认证、API 标准化、统一的可观测性以及供应商之间的智能路由功能。系统通过“首次令牌获取时间”(TTFT)、p90 延迟和 5xx 错误率等指标持续评估端点,将流量从性能下降的服务中重定向出去。该抽象层还支持 A/B 测试和受控的模型发布。
Slack 表示,最终构建的多云架构同时提升了性能和灵活性。除了已报告的质量和延迟方面的改进外,该公司还特别指出,他们能够访问更广泛的基础模型,增强了地理故障转移能力,并且降低了对任何单一云 AI 平台的依赖性。
Slack 的做法并非孤例。在 AI 基础设施领域,类似的多云策略正广泛涌现。例如,Padiso 的工程师通过将 Anthropic Claude 的流量路由至 Bedrock、Vertex AI 以及 Anthropic 的直接 API,提升了系统韧性并控制了对服务提供商的依赖。BentoML 也提倡基于延迟和可用性来路由流量的多云和跨区域推理策略。这些案例反映了与 Slack 所强调的可移植性、故障转移和运维灵活性相关的共同关切。
对于开发基于 AI 的应用程序的平台团队而言,Slack 的经验表明,抽象层既能帮助将应用逻辑与底层模型提供商分离,又能在韧性、性能以及对快速变化的模型生态系统的访问之间取得平衡。
文章来源:https://aidadog.com/news/ai/g78nns2bb7tq3qrjtd7fugmq
上一篇
文丨刘士武;36氪获悉;AI 创业公司「MobAI」已完成数百万元天使轮融资,由港股上市公司赤子城科技独家投资;目前,由MobAI开发的AI互动叙事应用Lunaverse Stories 已进入邀请制测试阶段;熟悉AI互动类产品的人应该对MobAI并不陌生;一年前,MobAI创始人钟文鼎(Vito)当时还在一家头部VC上班,工作之余和联创共同开发一款叫《修仙…
下一篇
36氪获悉,天眼查App显示,近日,重庆小马智行科技有限公司成立,法定代表人为张宁,注册资本3000万人民币,经营范围包括网络预约出租汽车经营服务、软件开发、人工智能基础软件开发、智能车载设备制造、新能源汽车整车销售等,由北京小马易行科技有限公司全资持股
同类推荐

OceanBase 推湖库一体架构:一套技术栈统一离在线,重新定义 AI 数据库
一套技术栈实现离在线统一
大厂研发组织大变革:前端后端合并,测试转型全栈,AI Coding 正在重塑工程师分工
点击查看原文>

小马智行彭军:Robotaxi落地十年长跑,运营效率才是车企盲区
2016年,彭军创立小马智行时,已经预料到,Robotaxi(自动驾驶出租车)从远景走进现实,实现大规模的落地,至少需要10年努力,要等待技术和法律法规的成熟,也要考虑社会的接受度;今天,不管是在旧金山街头穿梭的Waymo,还是在深圳南山闹市区接单的小马智行车队,都证实了这一点。自动驾驶车已然融入社会化车流,开始商业运营;但是彭军十年前可能没想到的是,制约其…

优必选超仿生机器人U1系列首发订单破万,最高售价99万元,人形机器人加速进入家庭
作者|黄楠;编辑|袁斯来;6月30日,优必选在2026年度全球发布会,正式推出全尺寸超仿生人形机器人“优世界”U1系列,包含半身版U1 Lite、高配全身版U1 Pro及高动态全身版U1 Ultra三款产品,售价区间为11.98万元至99万元;同时,优必选宣布,U1系列全渠道订单已累计突破13361台,成为全球首款具备规模化量产能力的全尺寸超仿生人形机器人…